Loading…
§ Case study · Armada Creative Director · 2026
On-brand marketing imagery, without a photoshoot.
An AI creative pipeline that generates 4K commercial imagery of security teams — locked to the company's real uniforms, patches, and fleet. Every image above and below is generated. Note the patch.
- Client
- Armada Security · Creative Director
- Industry
- AI · generative imagery
- Role
- Designed + built the pipeline: vision auto-tagging, brand-reference enforcement, Nano Banana generation, image-to-image refinement
- Year
- 2026
Image models drift. Ask one for a security guard and you get a great photo wearing the wrong patch, a golf cart instead of an SUV, gibberish text on a vehicle door. For a security brand, an image that wears the wrong badge isn’t a near-miss — it’s unusable. Armada Creative Director is the system I built to beat that drift: not a prompt that hopes for the best, but a closed loop that generates, scores its own output against brand rules, remembers every failure, and feeds those failures back so it stops repeating them.
Product & UX designGenerative imageryGoogle Gemini · Nano BananaQA-agent scoringRAG feedback loopPostgreSQLReact + Vite
The real problem: brand fidelity, not generation
Generating a plausible image is easy now. Generating one that wears Armada’s uniform, Armada’s patch on the correct shoulder, and the correct vehicle livery (every single time) is the actual job. A one-shot prompt can’t guarantee that, and a marketing asset with a hallucinated badge is worse than no asset. So the system is built around enforcement and self-correction, not around the prompt.
The interface I designed
My job here was to take a messy generative process (prompts, references, brand rules, scores, failures) and give it a surface a marketer can actually operate without writing a single prompt. Instead of a blank text box, the Concept builder is a set of structured controls (service mode, industry, location, time of day, weather, aesthetic, framing, aspect ratio). But the design decision I care about most is the panel that sits above the controls: Active RAG Constraints — the system showing the operator, in plain language, what it learned from its own past failures, before they generate anything.
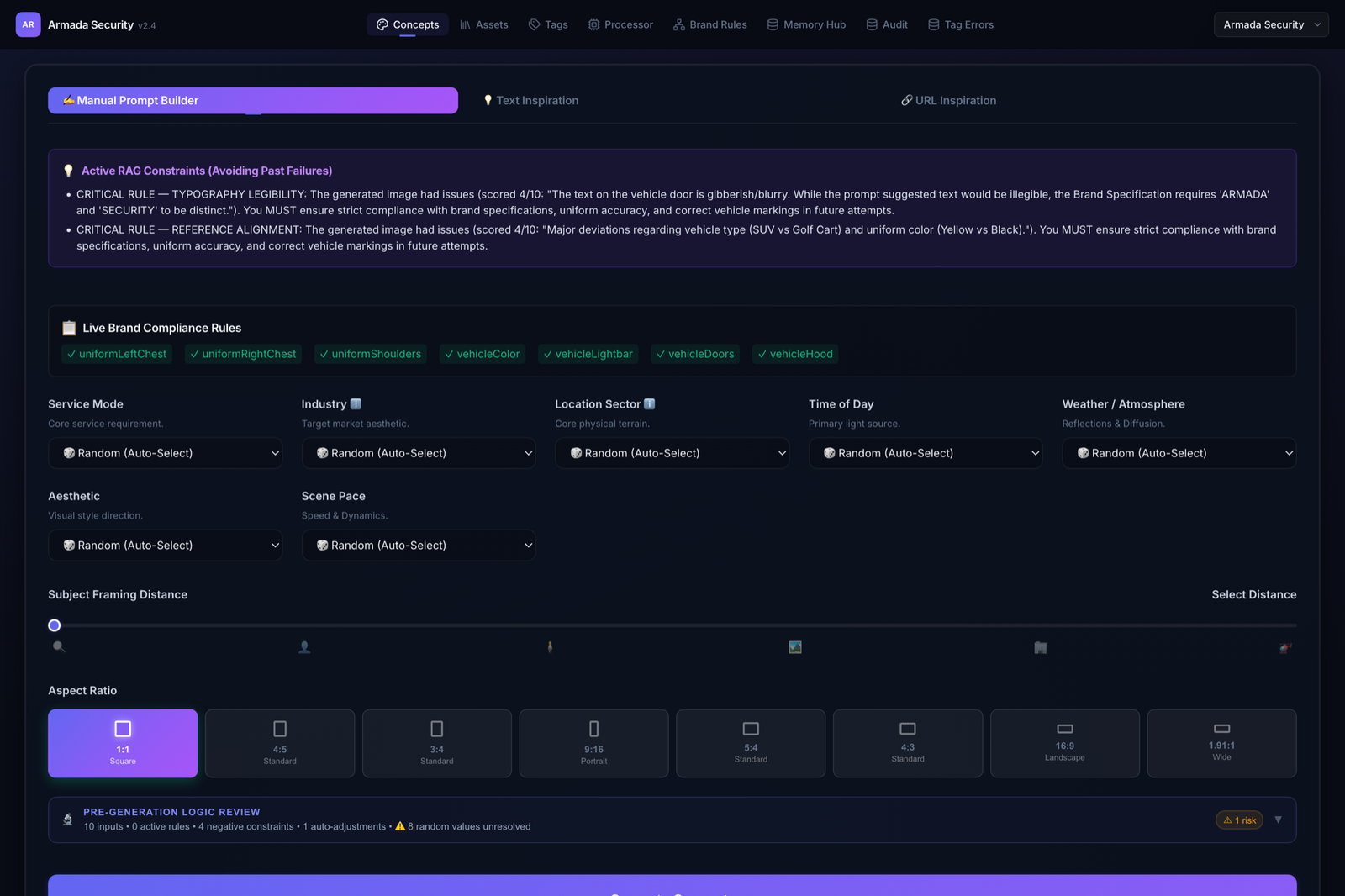
Two smaller design choices do a lot of work here. The green Live Brand Compliance Rules chips make the invisible visible — an operator can see exactly which brand constraints are active on this generation. And the Pre-generation Logic Review bar (“10 inputs · 0 active rules · 4 negative constraints · 8 random values unresolved · 1 risk”) turns an opaque AI call into a reviewable checklist before spending a generation. The interface is the guardrail.
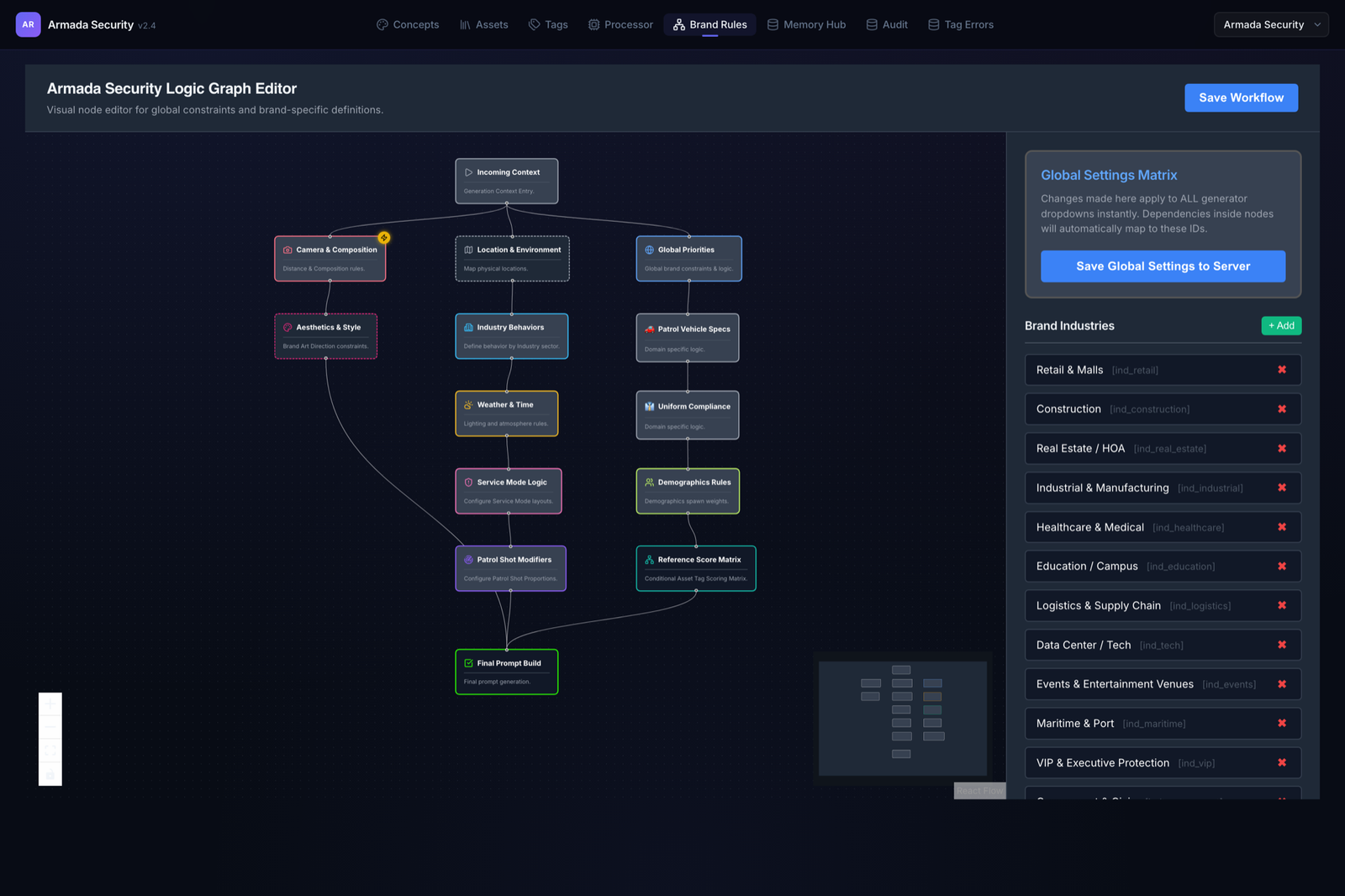
Designing brand rules as a graph, not a prompt
Brand fidelity can’t live inside a prompt string — it has to be authored, versioned, and checkable. So I designed the Brand Rules surface as a visual node graph: incoming context flows through brand and per-industry constraints into a final prompt build. A brand manager edits the rules by reshaping the graph, not by editing prose, which means the constraints that the QA agent later enforces are the same ones a human can read.
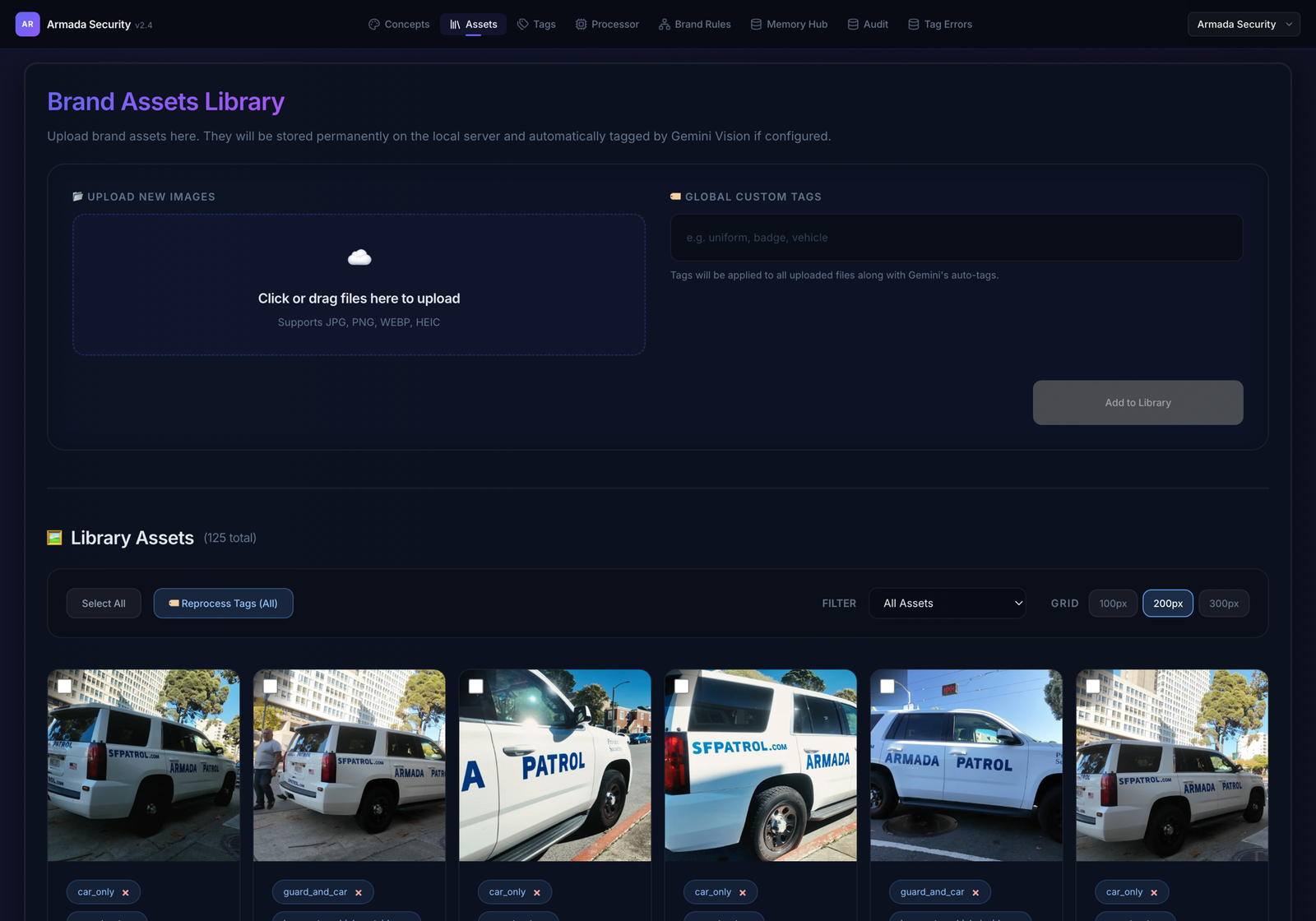
Underneath the generator sits the reference that keeps it honest: a vision-tagged Brand Assets Library. Real uniform and vehicle photos are uploaded once, auto-tagged by Gemini Vision (car_only, guard_and_car…), and become the anchor the model is forced to match — so “a guard” always means this guard, in this uniform, next to this livery.
The loop
The five pieces
- Brand Rules — a visual logic-graph editor. Brand and per-industry constraints (Retail, Construction, Healthcare, Logistics…) are authored as a node graph, not buried in prompts. Live compliance rules are explicit and checkable:
uniformLeftChest,uniformRightChest,uniformShoulders,vehicleColor,vehicleLightbar,vehicleDoors,vehicleHood. - Concept + auto-pick. Manual builder (service mode, industry, location, time of day, weather, aesthetic, framing) or URL-inspiration. When a guard is detected, the system fuzzy-matches the vision-tagged asset library and prepends the correct uniform and patch so the model is forced onto the real brand.
- Generation. Nano Banana (Gemini) with a hard reference anchor; the 20MB+ output is auto-compressed to WebP.
- QA agent — the gate. Each output is scored out of 10 against the brand rules. Low scores are flagged, not shipped. Real disputes from the system: a lobby scene scored 2/10; a night patrol-car shot scored 6/10.
- Memory Hub + RAG feedback. Every favorite, trash, dispute, and correction is logged to PostgreSQL and exportable as a reinforcement-learning dataset. Failures are distilled into the “Active RAG Constraints” the next generation must obey.
The system talking to itself
This is the part that makes it a platform instead of a prompt. Before each new generation, the builder surfaces the constraints it learned from past failures — in its own words:
CRITICAL RULE — TYPOGRAPHY LEGIBILITY: the generated image scored 4/10 (“text on the vehicle door is gibberish/blurry… ‘ARMADA’ and ‘SECURITY’ must be distinct”). Enforce brand-spec compliance and correct vehicle markings.
CRITICAL RULE — REFERENCE ALIGNMENT: scored 4/10 (“major deviations — SUV vs Golf Cart, uniform Yellow vs Black”). Enforce uniform accuracy and correct vehicle type.
That reframes the failures completely. Half of any raw generative batch is wrong — wrong text, wrong vehicle, wrong color. In a one-shot tool those are dead images. Here they’re the input that makes the next batch better. The errors aren’t the embarrassment; they’re the mechanism.
What passes the gate
When the loop works, the output is brand-accurate and shippable — real Armada patch, correct livery, 4K:

Why I built it as a system
It’s the visual half of a two-arm AI production setup — its sibling, Armada Content Director, generates the words; this generates the images, and they publish together. The conviction is identical: a one-click prompt produces generic junk you can’t trust; a system with explicit rules, a scoring gate, and a memory of its own mistakes produces something a business can actually ship. The QA-and-memory loop is the whole point — it’s the difference between “an image of a guard” and “a verified image of our guard.”
What I’d do differently
Promote the QA agent from advisory to a hard gate with auto-retry — on a failing score, regenerate with the new RAG constraint applied automatically, instead of surfacing it for the next manual run. And close the RL loop: the Memory Hub already exports a reinforcement-learning dataset, so the next step is fine-tuning on it rather than only steering via RAG at inference time.
Armada Creative Director — designed and built by Andrey Gurov, 2026. React + Vite · Node/Express · Google Gemini (concept, vision tagging, Nano Banana) · PostgreSQL · sharp. All interface screens and the hero are real captures from the running platform.